プログラム理解のための辞書の構築と提供
概要
ソフトウェアを使用するためには,ソフトウェアを作るだけでなく,利用者の要求や環境の変化に合わせてソフトウェアを変更するための多くのコストが必要になります. このようなソフトウェアの変更作業はソフトウェア保守と呼ばれます. さらに,ソフトウェア保守の中では対象のプログラムを理解するコストが半分以上を占めると言われています.
ここで,プログラムの理解に重要な役割を果たすのが,クラスや変数,関数などに付けられた識別子です. そのため,保守作業者が識別子の意味を理解できなかったり,誤解してしまったりすると,保守作業に莫大な時間が必要になってしまいます. しかし,プログラム中で使われる識別子や,それを構成する単語の意味を正しく理解できるようになるためには,長い経験が必要となります. なぜならば,プログラム中には専門用語などが頻出するため,一般の辞書 (自然言語の辞書) だけでは識別子の理解に不十分だからです.
そこで,この研究では,プログラム中で使われる単語の辞書を作ることで,ソフトウェアの開発・保守を支援することを目指しています. 具体的な研究の方針を以下に示します.
- 実際のプログラムから,識別子がどのように使われているかを記録した辞書を作成する
- 作成した辞書をソフトウェア設計者に提供し,識別子に分かりやすい名前を付ける作業を支援する
- 作成した辞書を保守作業者に提供し,識別子の意味を提示することでソフトウェア理解を助ける
現在は,主に1.の辞書作成を行なっています. また,作成した辞書を,プログラム理解以外の様々な用途に使うことも計画しています.
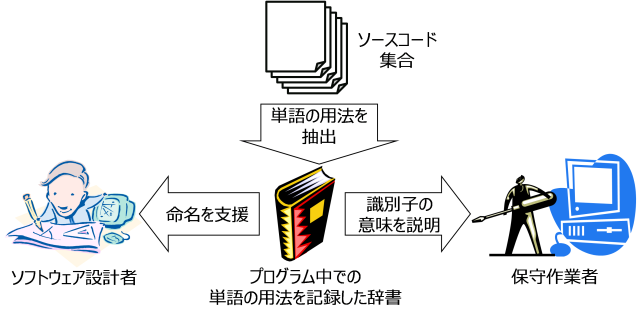
単語の説明文を記録した辞書の作成
前述のように,プログラムの中では一般の辞書に載っていない単語が多く現れます. そのような単語の例としては,プログラミングで慣用的に使われる単語や,開発組織に固有の単語,アプリケーションドメインの専門用語などがあります. そこで,このような単語の説明を,ソースコードを解析することで生成するのがこの研究の目的です.
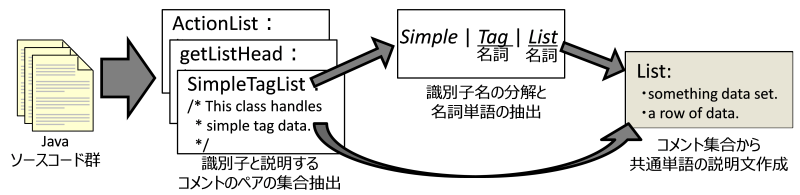
具体的には,ソースコード中に存在するドキュメントコメントと呼ばれる特殊なコメントを収集します. ドキュメントコメントとは,変数やクラス,メソッドなどのプログラム要素の役割を説明するコメントです. もちろん,ドキュメントコメントは単語を説明するためのものではないので,これだけでは単語の説明文にはなりません.
そこで,共通する単語を持った識別子を探し出し,それらを説明するドキュメントコメントから共通する部分を抜き出すことで,単語の説明を生成します.
単語間の関係を記録した辞書の作成
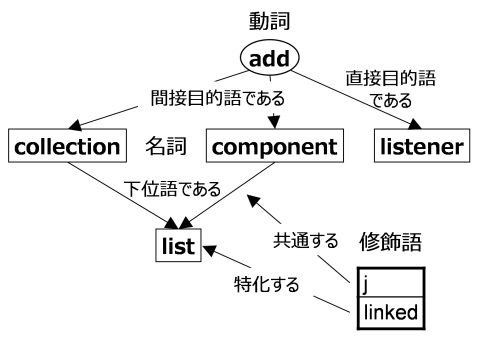
自然言語と同じように,ソースコードの中でも複数の単語を連携して用いることで複雑な意味を表現します. 例えば,メソッドとそれが所属するクラスの間には,動作とその主体という関係があります. そのため,プログラムを理解するためには,単語の意味を知るだけでなく,単語間の関係を理解しなければなりません.
一般に,単語間の関係を記録した辞書はシソーラスと呼ばれています. この研究では,プログラムの中で用いられる単語間の関係を記した辞書を作成することを目指しています. 具体的には,実際のソースコードを解析して得られたプログラム要素間の関係から,名詞の上位-下位関係(抽象-具象関係)や修飾-被修飾関係,動詞-目的語関係などを記録した辞書を作成しています.