<< Go back to the Research page.
Application of Competitive Programming to Machine Learning
With the rapid IT transformation, spurred by advancements in AI and IoT technologies, there has been a growing societal interest in programming education and training. As the demand for IT talent continues to rise, acquiring information literacy has become crucial. For instance, the latest curriculum guidelines in Japan now mandate phased programming education across elementary, junior high, and high schools nationwide. This trend has led to an increase in individual demand for programming education, with more people utilizing programming schools and online learning platforms.
In this article, we introduce research on the application of problems and solutions from competitive programming
— often used in programming education — as training data for machine learning.
Background
Competitive Programming
Competitive programming is a contest where participants write programs that meet specific requirements, competing for speed and accuracy. Multiple participants solve the same problem within a time limit and submit their source code online. Some websites adjust participants' ratings based on their performance in each contest, enabling users to enjoy programming in a game-like manner. In Japan, the well-known site AtCoder offers these contests, while globally, Codeforces is a popular option.
Competitive programming platforms have accumulated a large repository of problems and solutions from past contests (Figure 1). Solving these problems is beneficial not only for contest preparation but also for regular programming learning and education.
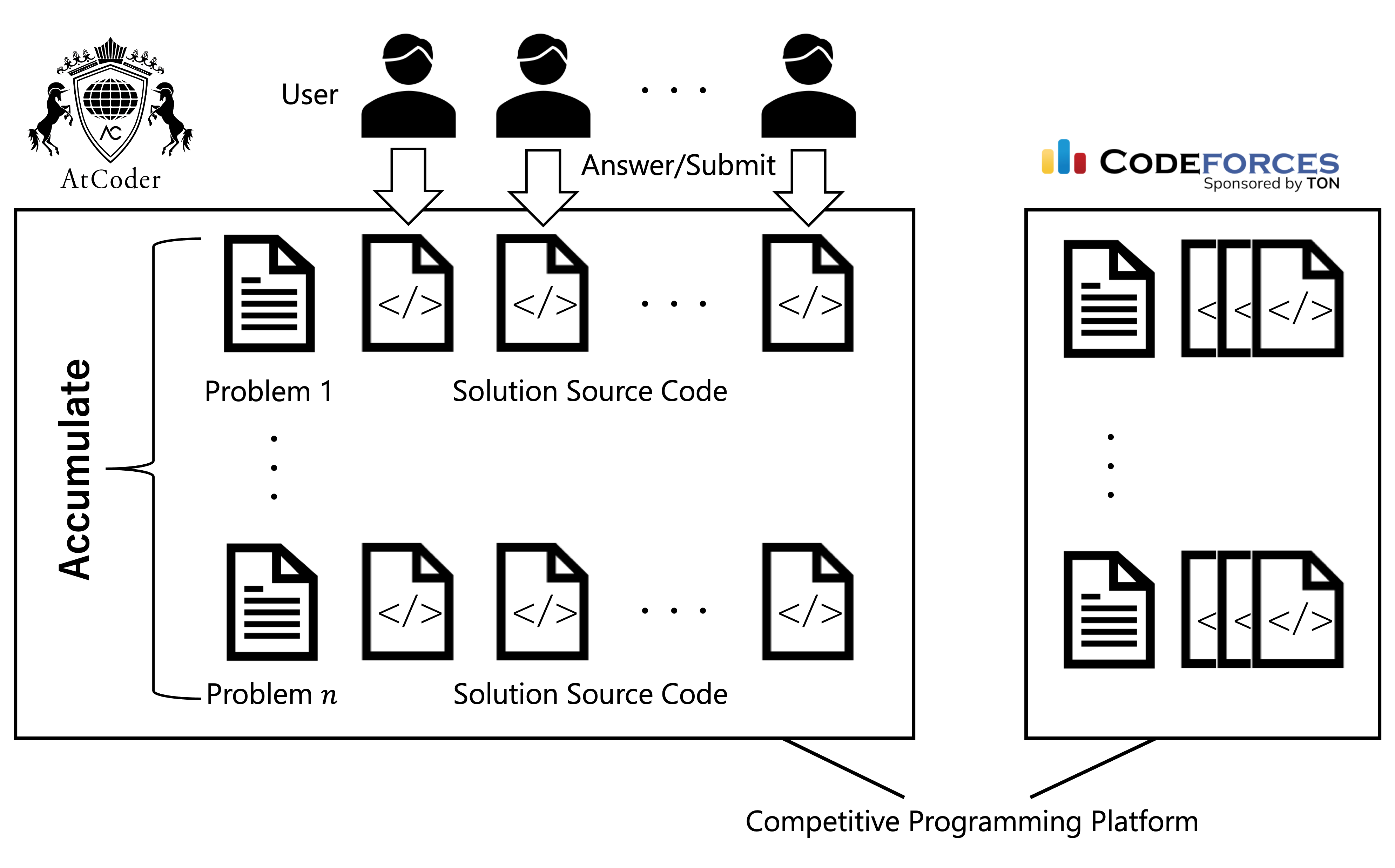
Machine Learning
Machine learning is a method for identifying common rules and patterns in large datasets, which can then be used to make predictions or inferences on new data. The use of machine learning in source code analysis has been expanding rapidly, and it is now widely applied in tasks such as code completion, bug repair, method naming, and translation between programming languages.
In recent years, Large Language Models (LLMs) pre-trained on extensive text corpora have garnered attention for their high versatility. One advantage of LLMs is that they can be fine-tuned with additional training data for specific tasks. Among these, OpenAI's GPT models have achieved notable success in natural language processing, with the widely adopted ChatGPT being fine-tuned specifically for conversational tasks.
Estimating Difficulty Across Different Platforms
When using competitive programming problems for learning, it is essential to select problems that match the learner's level. However, each platform currently employs its own difficulty metrics, making it challenging to find problems of equivalent difficulty across platforms. Research is underway to generalize difficulty levels and develop a unified method for estimating problem difficulty (Figure 2). In this study, we fine-tuned an existing model for difficulty estimation by using problem descriptions and example solution source codes.
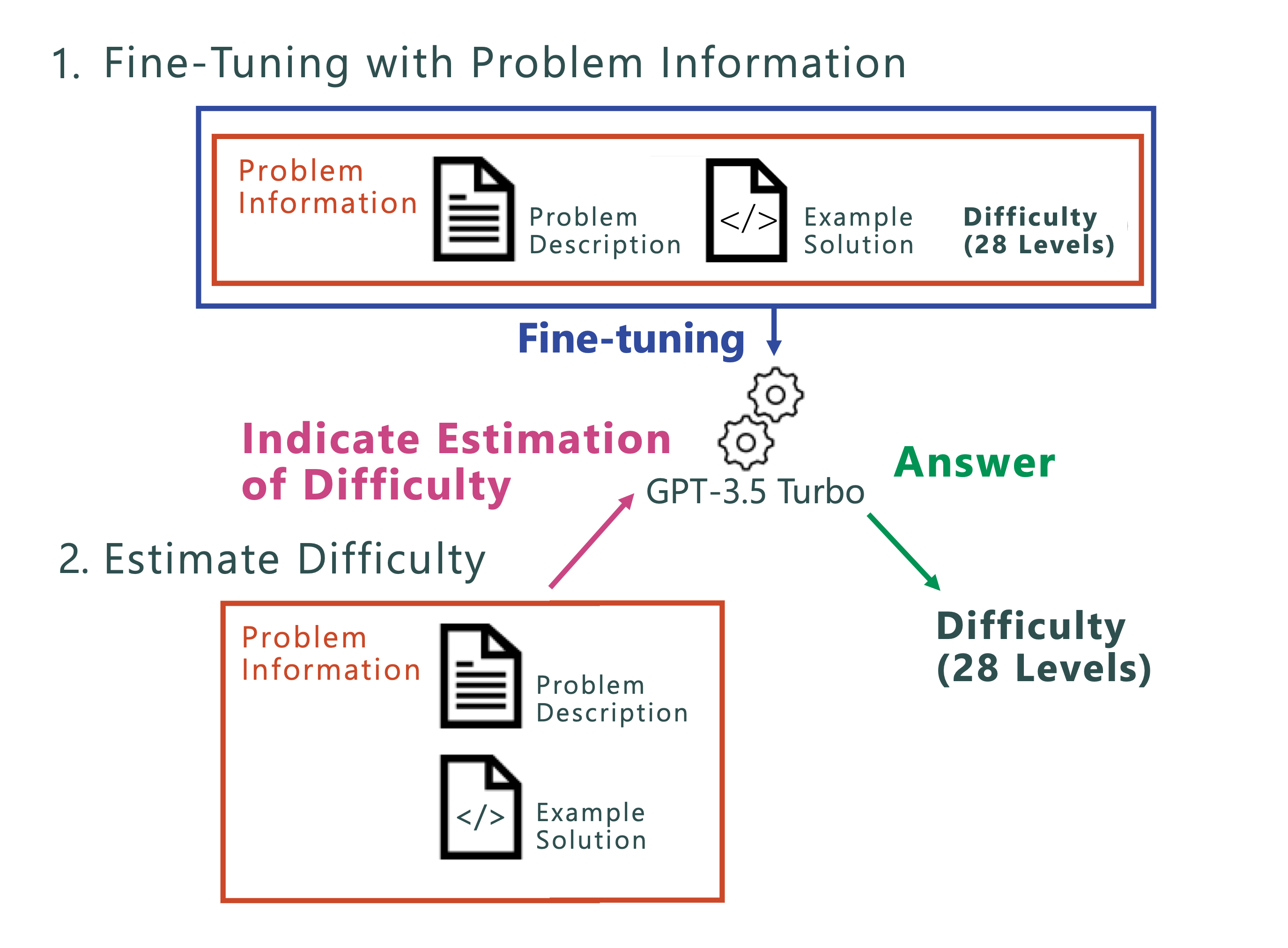
Experimental results indicate that fine-tuning contributes to improved accuracy in difficulty estimation, with the most effective results achieved when only problem statements were used to fine-tune the model. Moreover, it was found that difficulty estimation accuracy increased when using only problem statements as training data, rather than including example solution code.
Future challenges include:
- Improving datasets to leverage example solution source code
- Establishing appropriate standards for difficulty estimation
- Proposing methods to determine whether a given problem is solvable based on the learner's level
Related Papers
- Estimating the Difficulty of Programming Problems Using Fine-tuned LLM
- Chihiro Yoshida, Makoto Matsushita, Yoshiki Higo